前言
要春招了吖,随缘复习下Node的知识
NodeJS基本介绍
NodeJS是一种语言,但是如果你要找更确切的描述,那可以把它描述成一种Javascript的运行环境,能够使得Javascript脱离浏览器运行。
但是它比传统的浏览器JS拥有更多的功能,浏览器中的JS包括两个部分
WebAPI就是浏览器环境的提供的一些API,你在浏览器中能通过JS操作DOM,就是浏览器提供了DOM相关的API,还有setTimeout,fetch这些API。但是Web环境提供的功能非常有限,比如说你不能直接操作文件,进行HTTP请求时还要考虑同源策略,这些浏览器环境受限的地方(当然这是为了安全考虑,不然你上个网站,没准电脑里就多了一些奇奇怪怪的东西,那就不得了了)
而NodeJS就没有这些问题,和传统的后端语言一样,它几乎可以做到所有东西(包括文件操作,修改注册表等),可以对你的电脑做任意的操作,它包括下面的两个部分
Node API就是Node环境给NodeJS提供的API,详细的下面说
对比一下就行
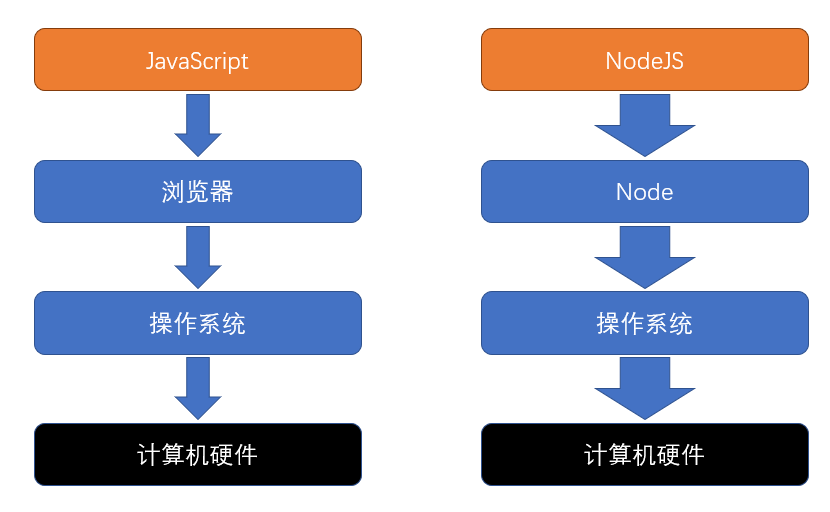
总结一下就是:
- 浏览器提供了有限的能力,JS只能使用浏览器提供的功能做有限的操作
- Node提供了完整的控制计算机的能力,NodeJS几乎可以通过Node提供的接口,实现对整个操作系统的控制
在学习了NodeJs后,你可以进行桌面端应用和服务端应用的开发了
服务端应用不用多说,但是桌面端应用,我可以举几个例子,比如vscode,steam,epic,这些都是用Electron这个库开发的
Node全局对象
http://nodejs.cn/api/globals.html#globals_global_objects
全局对象就算Global对象,打印一下如下(这里没有打印全,不止这么少)
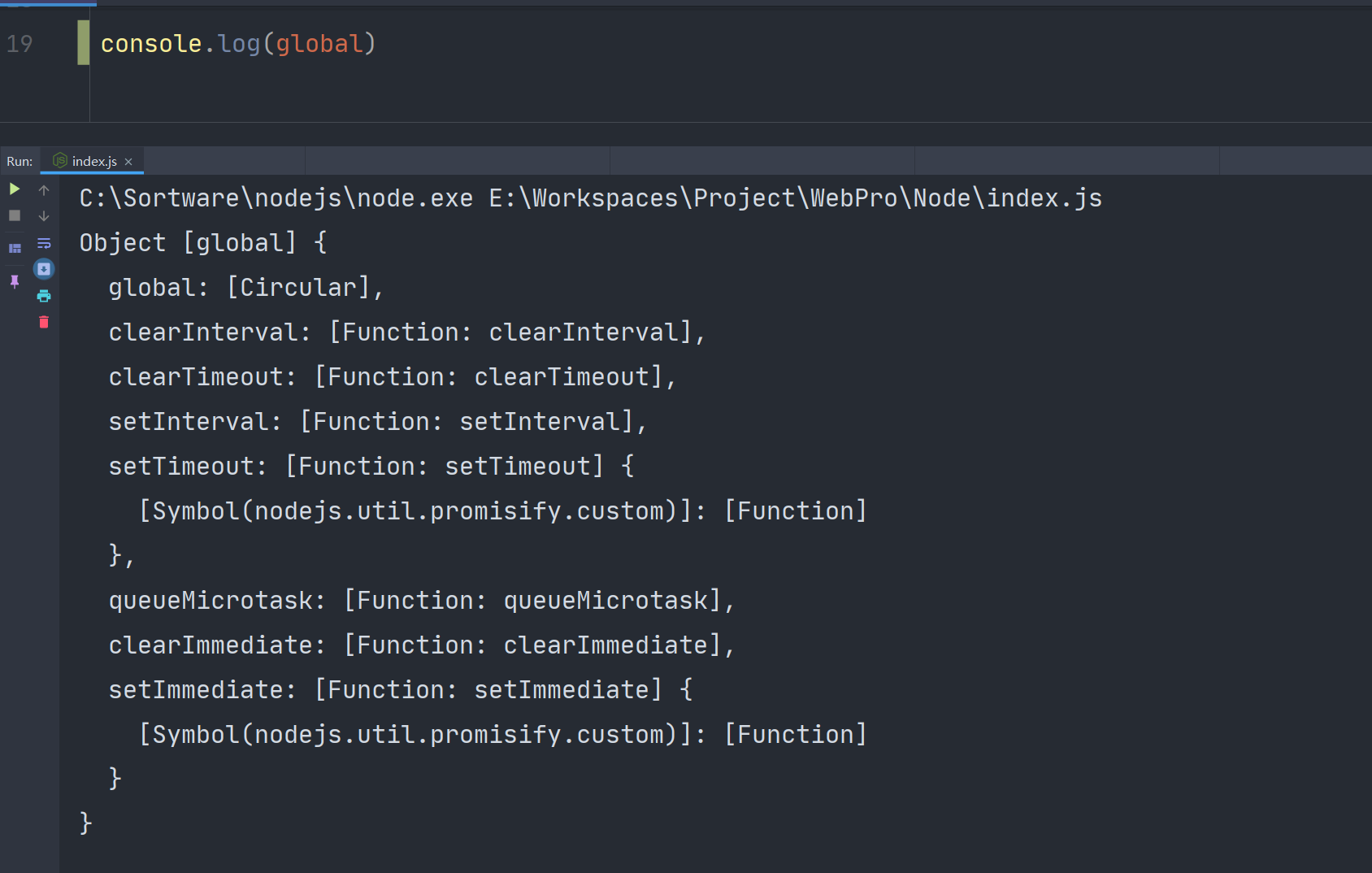
Global对象里的属性都是可以直接使用的
也许你会迷惑为什么global里还有一个global,因为global里的属性可以直接使用,但是global不做特殊操作的话就不能直接使用了,所以Node把global作为global的一个属性存起来了
这里只介绍process这个API,它的常见方法有下面几个
- cwd():返回当前nodejs进程的工作目录(绝对路径)
- exit():强制退出当前node进程,可以传递退出码给操作系统
- argv:string[]类型的数据,可以获取命令中的所有参数
- platform:获取当前的操作系统
- kill(pid):根据进程ID来kill进程
- env:获取环境变量对象
Node模块化
Node中的模块化用的是require和module.exports
require用于导入,module.exports用于导出
举个例子
./src/index.js
1
2
| let util = require("./util")
console.log(util.add(1,2));
|
./src/util/index.js
1
2
3
4
5
6
7
8
9
| function add(a, b) {
return a + b;
}
console.log("util index.js 执行", process.cwd())
module.exports = {
add
}
|
运行index.js
require
然后我们看一看require的一些查找规则
关于路径,你可以使用绝对路径,也可以使用相对路径,还可以使用一个单纯的包名
- 使用绝对路径,会直接进行模块加载
- 使用相对路径,会基于当前目录进行定位,转化为绝对路径再进行加载
- 使用包名(比如fs,axios这些),会进行下面的操作
- 检查是否为内置模块
- 检查当前目录的node_module
- 检查上级目录的node_module,如果还没找到,继续往上查找
- 找到后转化为绝对路径
- 模块加载
require可以对路径进行一些补全
补全后缀名,如果你只提供文件名不提供后缀名,会依次尝试进行使用下面的后缀名补全
补全文件名,如果你只提供了目录而没有提供文件名,会使用下面的方式进行查找
- 目录下没有package.json的话,查找index.js
- 否则查找package.json中的main字段,使用main字段指定的文件来补全
module
http://nodejs.cn/api/modules.html#modules_the_module_object
module 的变量是对表示当前模块的对象的引用。
修改一下代码
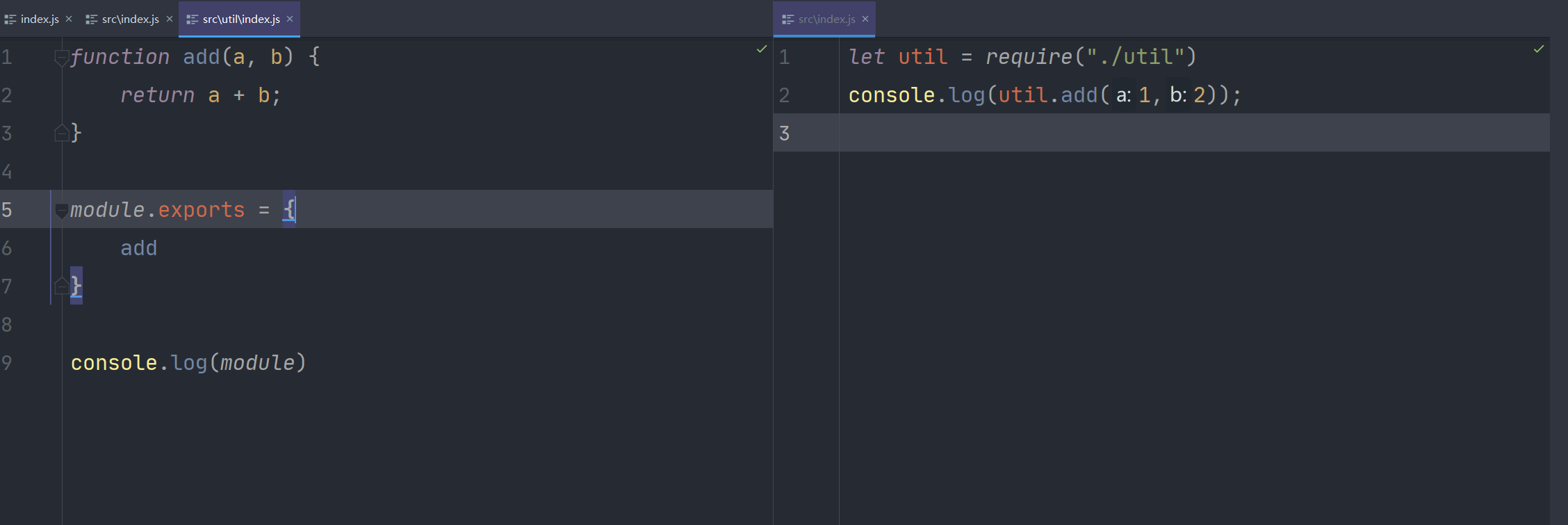
运行index,查看输出结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| Module {
id: 'E:\\Workspaces\\Project\\WebPro\\Node\\src\\util\\index.js',
path: 'E:\\Workspaces\\Project\\WebPro\\Node\\src\\util',
exports: { add: [Function: add] },
parent: Module {
id: '.',
path: 'E:\\Workspaces\\Project\\WebPro\\Node\\src',
exports: {},
parent: null,
filename: 'E:\\Workspaces\\Project\\WebPro\\Node\\src\\index.js',
loaded: false,
children: [ [Circular] ],
paths: [
'E:\\Workspaces\\Project\\WebPro\\Node\\src\\node_modules',
'E:\\Workspaces\\Project\\WebPro\\Node\\node_modules',
'E:\\Workspaces\\Project\\WebPro\\node_modules',
'E:\\Workspaces\\Project\\node_modules',
'E:\\Workspaces\\node_modules',
'E:\\node_modules'
]
},
filename: 'E:\\Workspaces\\Project\\WebPro\\Node\\src\\util\\index.js',
loaded: false,
children: [],
paths: [
'E:\\Workspaces\\Project\\WebPro\\Node\\src\\util\\node_modules',
'E:\\Workspaces\\Project\\WebPro\\Node\\src\\node_modules',
'E:\\Workspaces\\Project\\WebPro\\Node\\node_modules',
'E:\\Workspaces\\Project\\WebPro\\node_modules',
'E:\\Workspaces\\Project\\node_modules',
'E:\\Workspaces\\node_modules',
'E:\\node_modules'
]
}
|
我们这里对一些属性进行介绍
- id:模块的标识符。 通常是完全解析后的文件名。
- loaded:模块是否已经加载完成,或正在加载中。
- path:模块的目录
- child:模块引用了哪些子模块
- exports:模块的导出
模块化细节
我们用一个例子来引入
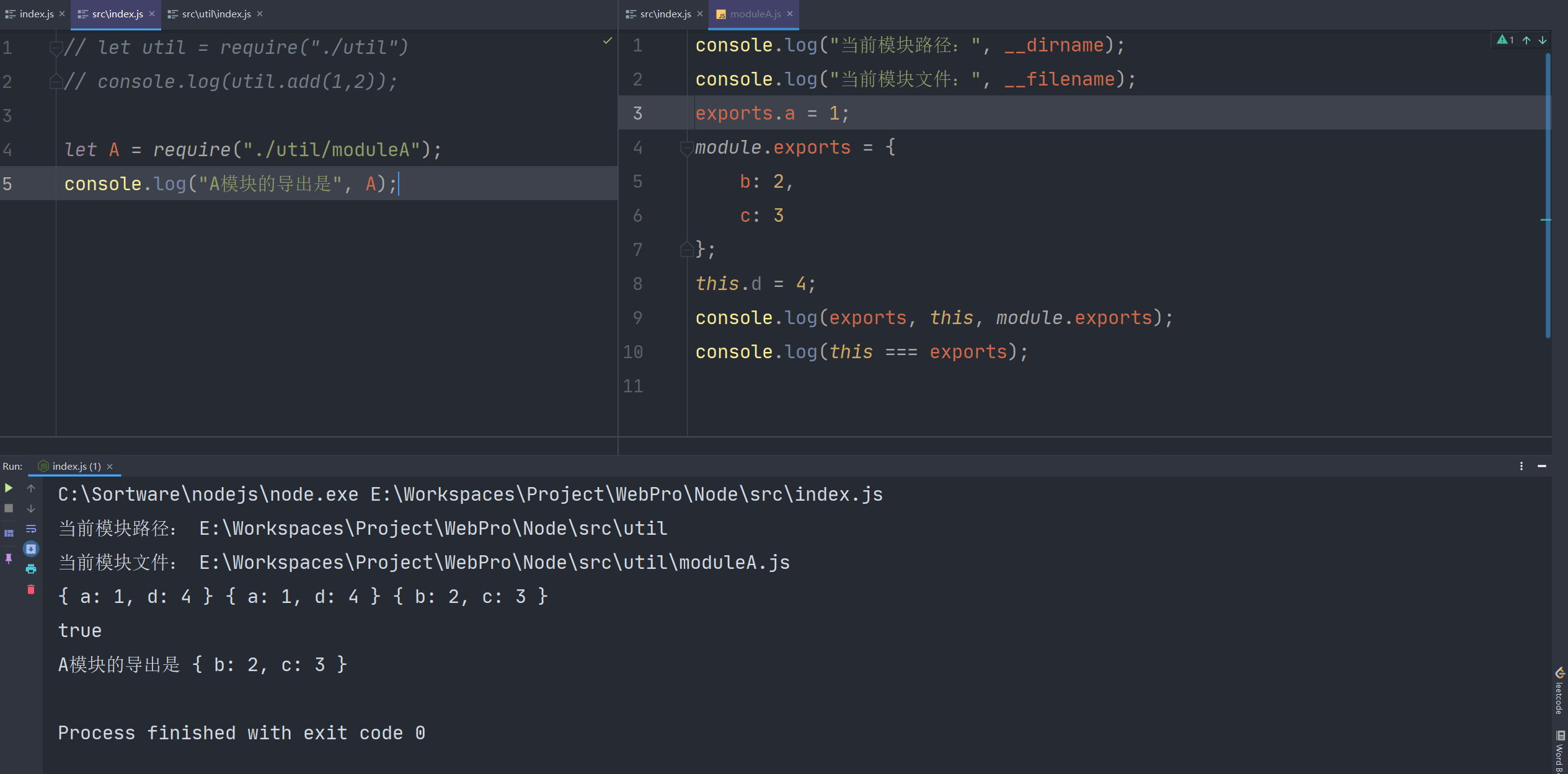
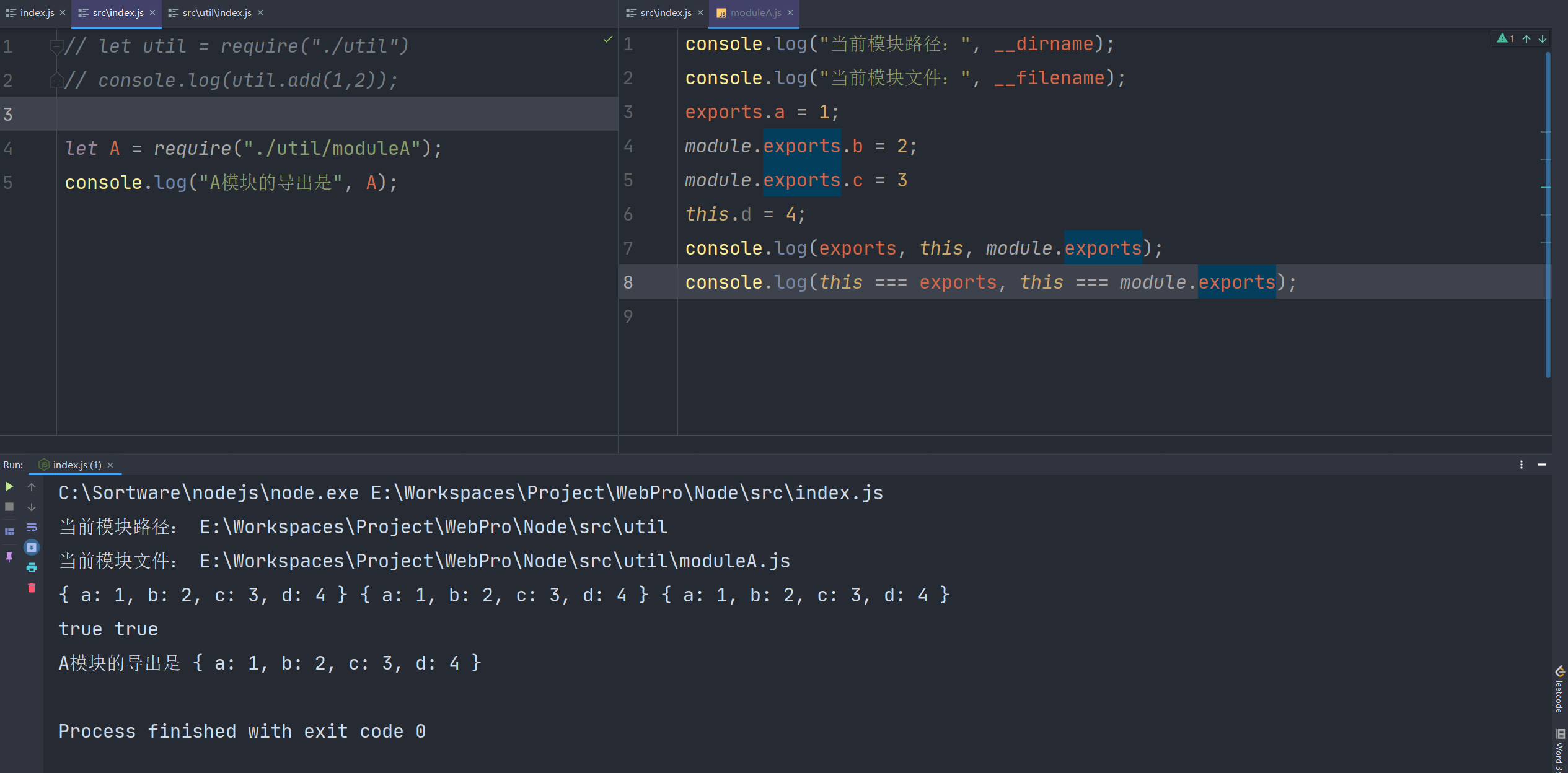
为什么如此相似的代码会产生这样的结果呢,那就要说说模块的导入机制了
我们用伪代码来表示这个过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| require("./util/moduleA");
function require(modulePath) {
modulePath = Normalization(modulePath);
if (require.cache[modulePath]) {
return require.cache[modulePath];
}
let content = readFile(modulePath);
const __temp = new Function('module', 'exports', 'require', '__dirname', '__filename', content);
let module = {
}
module.exports = {};
const exports = module.exports;
__temp.call(module.exports, module, exports, require, module.path, module.filename)
return require.cache[modulePath] = module.exports;
}
|
从代码中可以看出
模块中的this,module.exports和exports最初指向的是一个对象
但是最后导出的是module.exports,如果你给module.exports重新赋值了,其他两个就失效了
所以我们最好只使用这三者中的一个,且不要给exports重新赋值
如果你不是很理解,参见下面的代码
1
2
3
4
5
6
7
8
9
10
11
| let a = {};
let b = a, c = a;
b = {};
b.name = "sena";
c = {};
c.name = "sakura";
a = {};
a.name = "snow";
console.log(a);
|
Node内置模块
这里我就不具体详细介绍每个模块的API了
反正都只是copy文档,直接放文档链接好了
os
http://nodejs.cn/api/os.html#os_os
os 模块提供了与操作系统相关的实用方法和属性,可以获取CPU信息,可用内存等。
1
| const os = require("os");
|
path
http://nodejs.cn/api/path.html#path_path
path 模块提供了一些实用工具,用于处理文件和目录的路径(注意,只是对路径进行处理,不会检查是否真的存在这个路径)。
1
| const path = require('path');
|
url
http://nodejs.cn/api/url.html#url_url
url 模块用于处理与解析 URL。
1
| const url = require('url');
|
util
http://nodejs.cn/api/util.html#util_util
util 模块用于支持 Node.js 内部 API 的需求。 大部分实用工具也可用于应用程序与模块开发者。 使用方法如下:
1
| const util = require('util');
|
文件IO
我们先了解一下IO的概念,这里的I/O指的是input/output,也就是输入输出,而输出输出的对象一般是CPU和外部设备
外部设备主要有
当然这里我们只介绍文件IO,因为对于前端来说,最常用的就是文件IO了
操作文件,我们需要用到Node提供的一个包fs
http://nodejs.cn/api/fs.html#fs_file_system
fs 模块可用于与文件系统进行交互
使用下面的代码来获取fs模块
1
| const fs = require('fs');
|
下面列举一些常用的API
读取文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| const fs = require("fs");
const path = require("path");
const filename = path.resolve(__dirname, "./myfiles/1.txt");
fs.readFile(filename, "utf-8", (err, content) => {
console.log("异步读取:", content);
});
const content = fs.readFileSync(filename, "utf-8");
console.log("同步读取:",content);
async function test() {
const content = await fs.promises.readFile(filename, "utf-8");
console.log("promise读取:",content);
}
test();
|
写入文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| const fs = require("fs");
const path = require("path");
const filename = path.resolve(__dirname, "./myfiles/2.txt");
fs.writeFile(filename, "这是文件内容", {
flag: "w"
}, function (err, content) {
console.log(err, content);
})
fs.writeFileSync(filename, "文件内容");
async function test() {
await fs.promises.writeFile(filename, "阿斯顿发发放到发", {
flag: "a"
});
const buffer = Buffer.from("abcde", "utf-8");
await fs.promises.writeFile(filename, buffer);
console.log("写入成功");
}
|
获取文件或目录信息
这里我们使用fs.stat
使用方式如下
1
2
3
4
5
6
7
8
9
| const fs = require("fs");
const path = require("path");
const filename = path.resolve(__dirname, "./myfiles/");
async function test() {
const stat = await fs.promises.stat(filename);
console.log(stat);
console.log("是否是目录", stat.isDirectory());
console.log("是否是文件", stat.isFile());
}
|
还是挺简单的,再介绍一下其他的属性
- size: 占用字节
- atime:上次访问时间
- mtime:上次文件内容被修改时间
- ctime:上次文件状态被修改时间
- birthtime:文件创建时间
- isDirectory():判断是否是目录
- isFile():判断是否是文件
获取目录中的文件和子目录
1
2
3
4
5
6
7
8
9
10
11
12
| const fs = require("fs");
const path = require("path");
const dirname = path.resolve(__dirname, "./myfiles/");
async function test() {
const paths = await fs.promises.readdir(dirname);
console.log(paths);
}
test();
|

创建目录
使用mkdir创建目录
1
2
3
4
5
6
7
8
9
10
| const fs = require("fs");
const path = require("path");
const dirname = path.resolve(__dirname, "./myfiles/1");
async function test() {
await fs.promises.mkdir(dirname);
console.log("创建目录成功");
}
test();
|
判断文件或目录是否存在
因为fs.exists已经弃用,所以可以使用fs.stat或者fs.access
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| async function exists(filename) {
try {
await fs.promises.stat(filename);
return true;
} catch (err) {
if (err.code === "ENOENT") {
return false;
}
throw err;
}
}
async function test() {
const result = await exists(dirname);
if (result) {
console.log("目录已存在");
} else {
await fs.promises.mkdir(dirname);
console.log("目录创建成功");
}
}
|
复制文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| const fs = require("fs");
const path = require("path");
async function copy(fromFilename, toFilename) {
try {
const buffer = await fs.promises.readFile(fromFilename);
await fs.promises.writeFile(toFilename, buffer);
return null;
}catch (e) {
throw e;
}
}
async function test() {
try {
await copy(path.resolve(__dirname, "./myfiles/1.jpeg"), path.resolve(__dirname, "./myfiles/1.copy.jpeg"))
}catch (e) {
console.log(e);
}
}
test();
|
文件流
先介绍流的概念,流是指数据的流动,数据从一个地方缓缓的流动到另一个地方
一般来说,下面两种情况会用上流
- 其他介质和内存的数据规模不一致(比如你不能把磁盘里的一个视频完全读到内存里播放)
- 其他介质和内存的数据处理能力不一致(比如把内存中快速的数据存到速度较慢的硬盘中)
- 不需要完全加载完毕就可以进行其他操作的情况(比如浏览器加载HTML,是边下载边解析的,还有就是,如果你看一个视频,你可以指定从那个节点开始看,就是因为流可以指定从哪里开始读取)
其实这个流概念比较抽象,我们接下来直接介绍下文件可读流和文件可写流
文件可读流
可用选项:http://nodejs.cn/api/fs.html#fs_fs_createreadstream_path_options
可读流:http://nodejs.cn/api/stream.html#stream_class_stream_readable
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| const fs = require("fs");
const path = require("path");
const filename = path.resolve(__dirname, "./data.txt");
const rs = fs.createReadStream(filename, {
encoding: "utf-8",
highWaterMark: 1,
autoClose: true
});
rs.on("open", () => {
console.log("文件被打开了");
});
rs.on("error", () => {
console.log("出错了!!");
});
rs.on("close", () => {
console.log("文件关闭了");
});
rs.on("data", chunk => {
console.log("读到了一部分数据:", chunk);
rs.pause();
});
rs.on("pause", () => {
console.log("暂停了");
setTimeout(() => {
rs.resume();
}, 1000);
});
rs.on("resume", () => {
console.log("恢复了");
});
rs.on("end", () => {
console.log("全部数据读取完毕");
});
|
这段程序会每隔一秒打印一个从文件里读出的字,也就是意味着数据是缓慢流动的
文件可写流
可用选项:http://nodejs.cn/api/fs.html#fs_fs_createwritestream_path_options
可写流:http://nodejs.cn/api/stream.html#stream_class_stream_writable
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| const fs = require("fs");
const path = require("path");
const filename = path.resolve(__dirname, "./temp/data.txt");
const ws = fs.createWriteStream(filename, {
encoding: "utf-8",
highWaterMark : 7,
autoClose : true
});
let content = "雪之樱SakuraSnow"
let index = 0;
let contentLength = content.length;
function write() {
let flag = true;
while ((index < contentLength) && flag) {
flag = ws.write(content[index]);
console.log(flag)
index++;
}
if (index === contentLength) {
ws.end(() => {
console.log("写入完成");
})
}
}
ws.on("drain", () => {
console.log("队列清空");
write();
});
write();
|
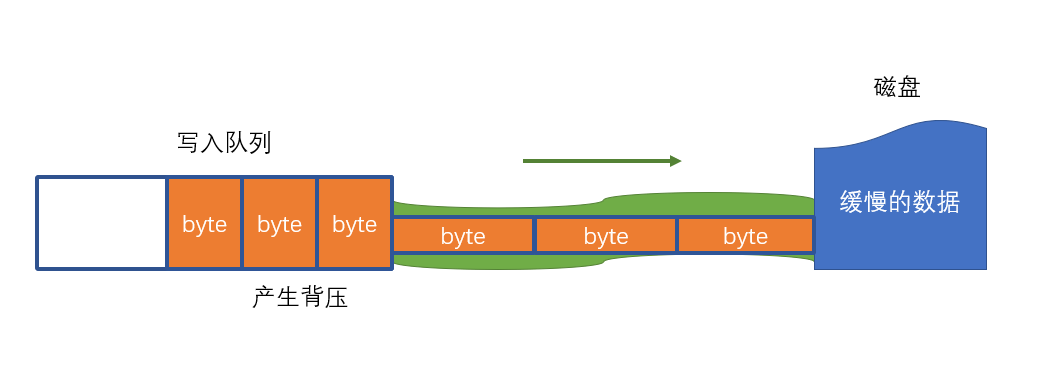
控制台输出如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| true
true
false
队列清空
true
true
true
true
true
true
false
队列清空
true
true
true
写入完成
|
改进复制文件
如果我们要复制一个大文件,使用之前的方法进行复制就不大合适了,因为之前的方法会把整个文件的内容读到内存,文件几个G的时候,就不大可行了
我们可以使用流的方式来改进
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| const fs = require("fs");
const path = require("path");
async function copy(from, to) {
console.log("开始复制");
const rs = fs.createReadStream(from);
const ws = fs.createWriteStream(to);
rs.on("data", chunk => {
const flag = ws.write(chunk);
if (!flag) {
rs.pause();
}
});
ws.on("drain", () => {
rs.resume();
});
rs.on("close", () => {
ws.end();
console.log("复制完成");
});
}
copy(path.resolve(__dirname, "./temp/data.txt"), path.resolve(__dirname, "./temp/data-copy.txt"));
|
http模块
http://nodejs.cn/api/http.html#http_http
http模块用于创建HTTP 服务器和客户端,如果你要创建基于tcp的客户端,使用net模块
因为我们一般很少直接使用http模块(一般会用express或者koa这样的框架),所以就举个例子,如果你想看更多API可以看看文档
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
const http = require("http");
const request = http.request(
"http://service.picasso.adesk.com/v1/vertical/vertical",
{
method: "GET"
},
resp => {
console.log("服务器响应的状态码", resp.statusCode);
console.log("服务器响应头", resp.headers);
let result = "";
resp.on("data", chunk => {
result += chunk.toString("utf-8");
});
resp.on("end", chunk => {
console.log(JSON.parse(result));
});
}
);
request.end();
|
客户端接收数据是基于流的,所以,你也要使用和处理流类似的方法处理数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| const http = require("http");
const url = require("url");
function handleReq(req) {
console.log("接收到请求");
const urlobj = url.parse(req.url);
console.log("请求路径", urlobj);
console.log("请求方法", req.method);
console.log("请求头", req.headers);
let body = "";
req.on("data", chunk => {
body += chunk.toString("utf-8");
});
req.on("end", () => {
console.log("请求体", body);
});
}
const server = http.createServer((req, res) => {
handleReq(req);
res.setHeader("a", "1");
res.setHeader("b", "2");
res.setHeader("content-type", "application/json")
res.statusCode = 200;
res.write(JSON.stringify({
name : "SakuraSnow"
}));
res.end();
});
server.listen(9000);
server.on("listening", () => {
console.log("server listen 9000");
});
|
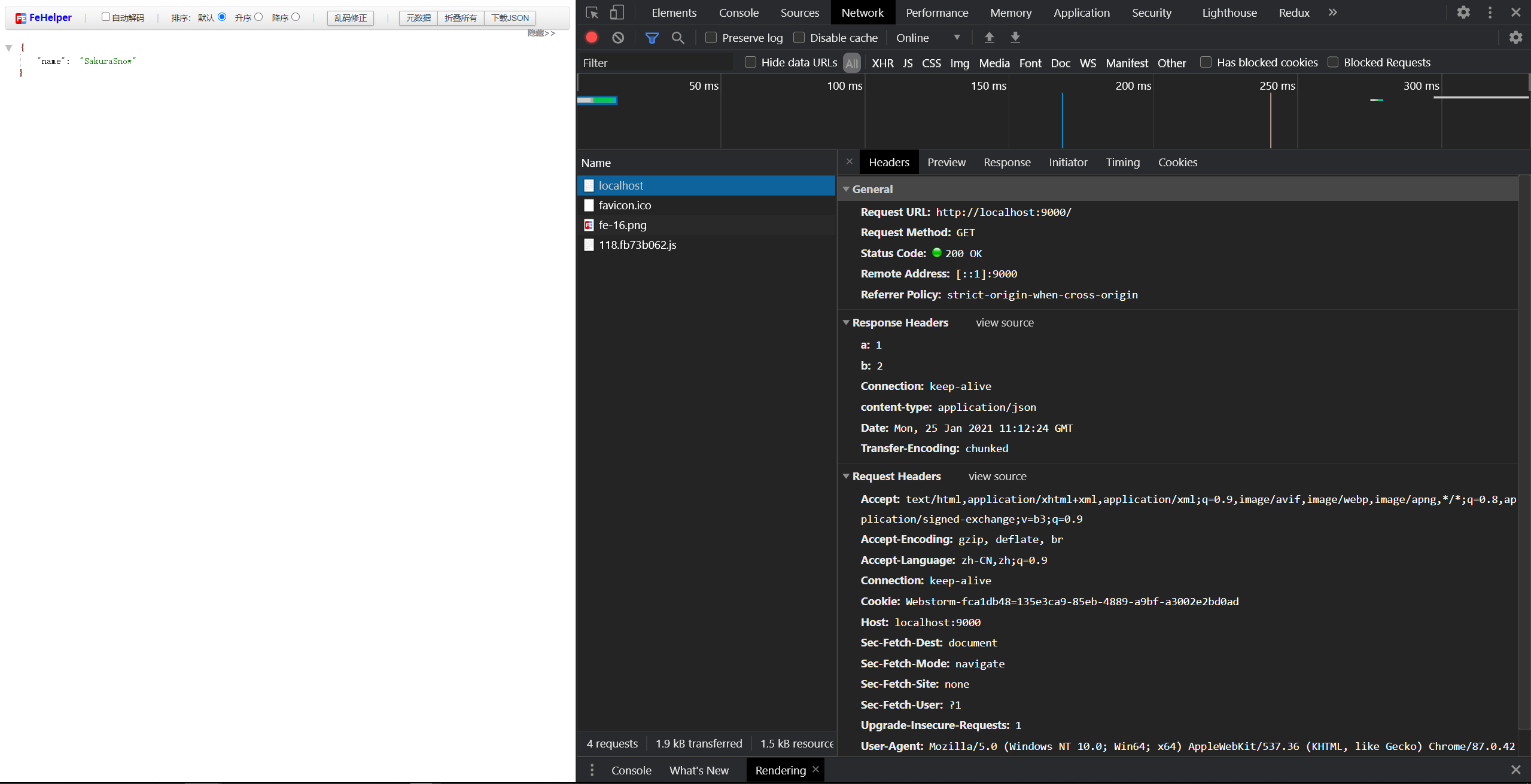
运行代码后,可以在浏览器中输入localhost:9000查看
Node的生命周期
开局一张图, 内容全靠编
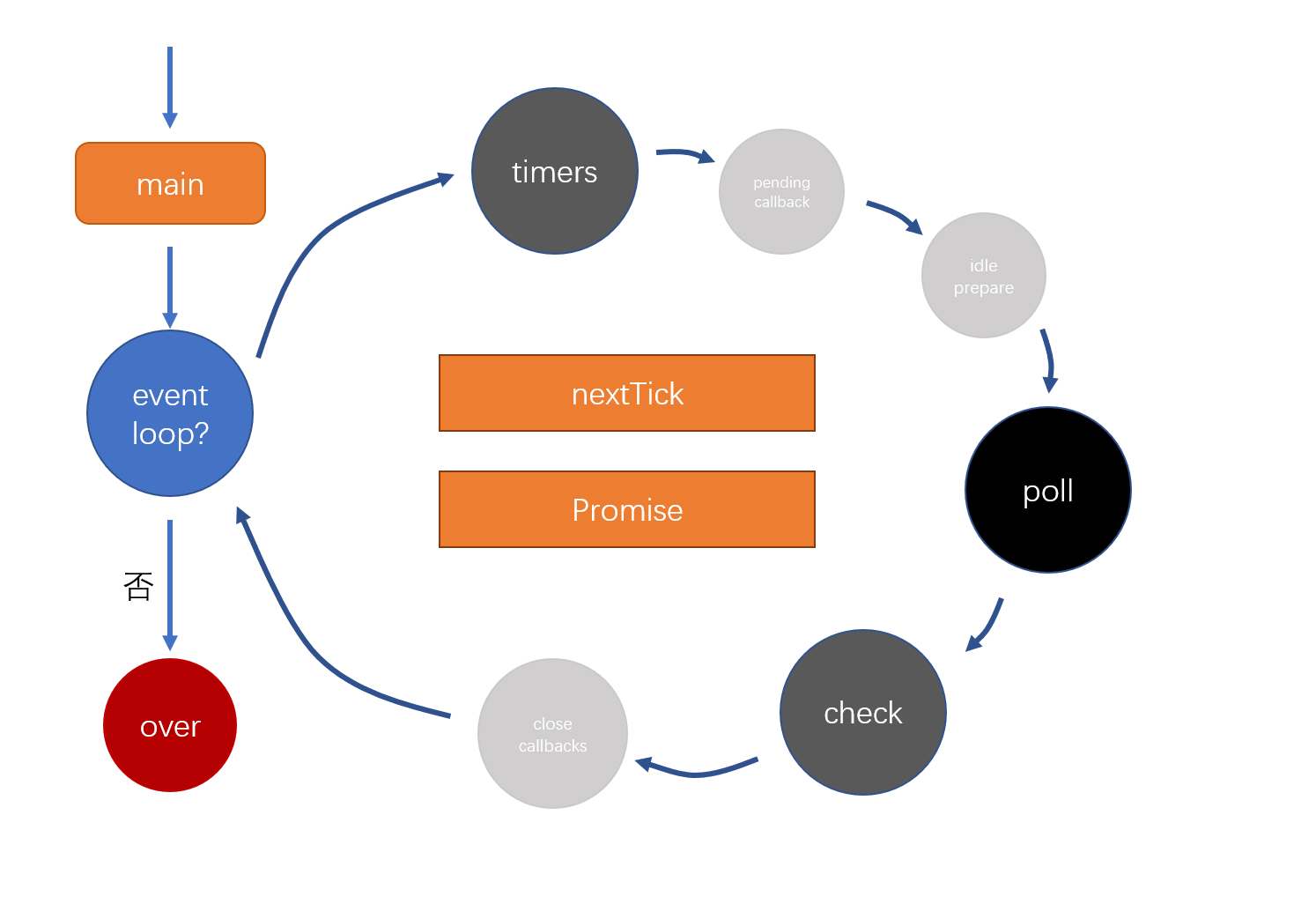
在同步脚本运行完后,就开始了event loop阶段,也就是事件轮询阶段
NodeJS里,每一种类型的事件都有一个队列,这里我们只关注timers,poll,check
- timers:存放计时器的回调函数(PS:setTimeout的time最小是1)
- poll:轮询队列(绝大部分回调都会放入该队列,比如:文件的读取、用户的网络请求)
- check:检查阶段(使用setImmediate的回调会直接进入这个队列,PS:setTimeout要进行计时,效率没有setImmediate高)
poll的运作方式非常特殊
首先,如果poll中有回调,依次执行回调,直到清空队列,这点和其他的一样
但是如果poll中没有回调,就会有下面的操作
- 如果其他队列也没有回调,持续等待(就一直卡在poll阶段),直到出现回调
- 等待其他队列中出现回调,结束该阶段,进入下一阶段
另外,中间还有两个特殊的事件队列,实际上有下面的规则
- 事件循环中,每次打算执行一个回调之前,必须要先清空NextTick和Promise队列
可以康康下面的面试题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| setImmediate(() => {
console.log(1);
});
process.nextTick(() => {
console.log(2);
process.nextTick(() => {
console.log(6);
});
});
console.log(3);
Promise.resolve().then(() => {
console.log(4);
process.nextTick(() => {
console.log(5);
});
});
|
答案是:3,2,6,4,5,1
FAQ
Java和Node性能比较
Node的官网
中文网
Electron
