前言
这是一篇刷题笔记,不定期更新,看到有趣的题就会记录一下
面试
Object.freeze
1 | const box = { |
Object.freeze() 方法可以冻结一个对象。一个被冻结的对象再也不能被修改;
也就是说冻结了一个对象则不能向这个对象添加新的属性,不能删除已有属性,不能修改已有属性的值,不能修改该对象已有属性的可枚举性、可配置性、可写性。
- 非严格模式下只是修改无效
- 严格模式下会报错
TypeError
另外,冻结是浅层的,可以使用递归完全冻结
顺带一提Object.seal可以防止属性被添加或者被移除,不能防止属性的值被修改
ParseInt
它可以用来把一个字符串转化成数字,参数如下
- 要解析的字符串
- 解析的字符串是什么进制
这里只介绍三种特殊的规则
- 进制无效 或者 无法按照传入进制解析时会返回NaN
1 | parseInt('7', 1) // NaN |
- 不指定进制时默认是10进制
1 | parseInt('10') // 10 |
- 解析到不合法的字符会停止解析并跳过后面的所有字符
1 | parseInt("7*6") // 7 |
假值
JavaScript中仅有6个假值
- undefined
- null
- NaN
- 0
- ‘’(空字符串)
- false
下面这些都不是假值
- ‘ ‘
- new Boolean(false)
- new Number(0)
HTML
Doctype作用
声明位于HTML文档中的第一行,处于 标签之前。告知浏览器的解析器用什么文档标准解析这个文档。
在标准模式中,排版和JS运作模式都是以该浏览器支持的最高标准运行。在兼容模式中,页面以宽松的向后兼容的方式显示,模拟老式浏览器的行为
比如同样是500px宽高的图片,因为在标准模式中的基线对齐问题,会让父容器高出几个px
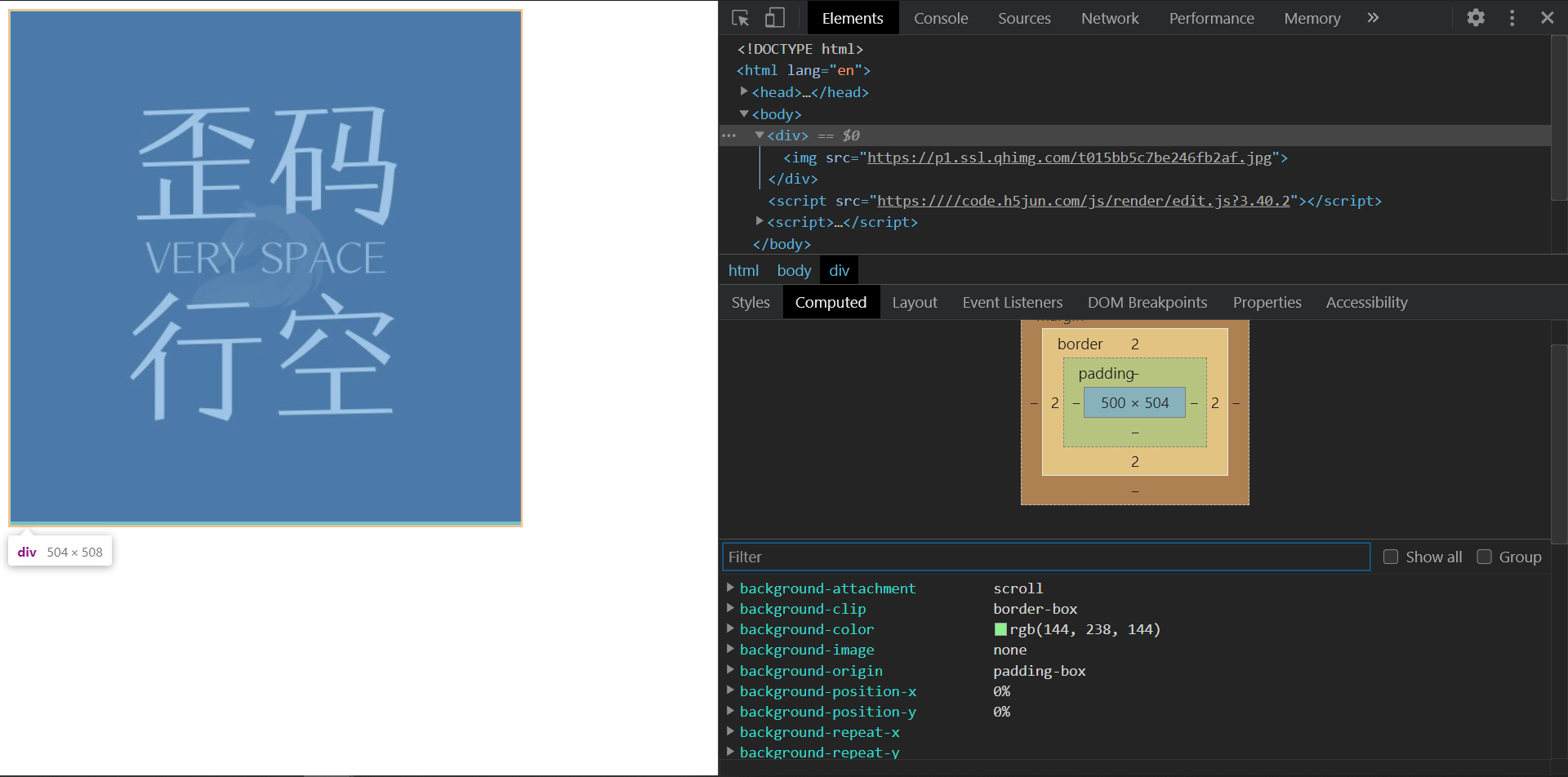
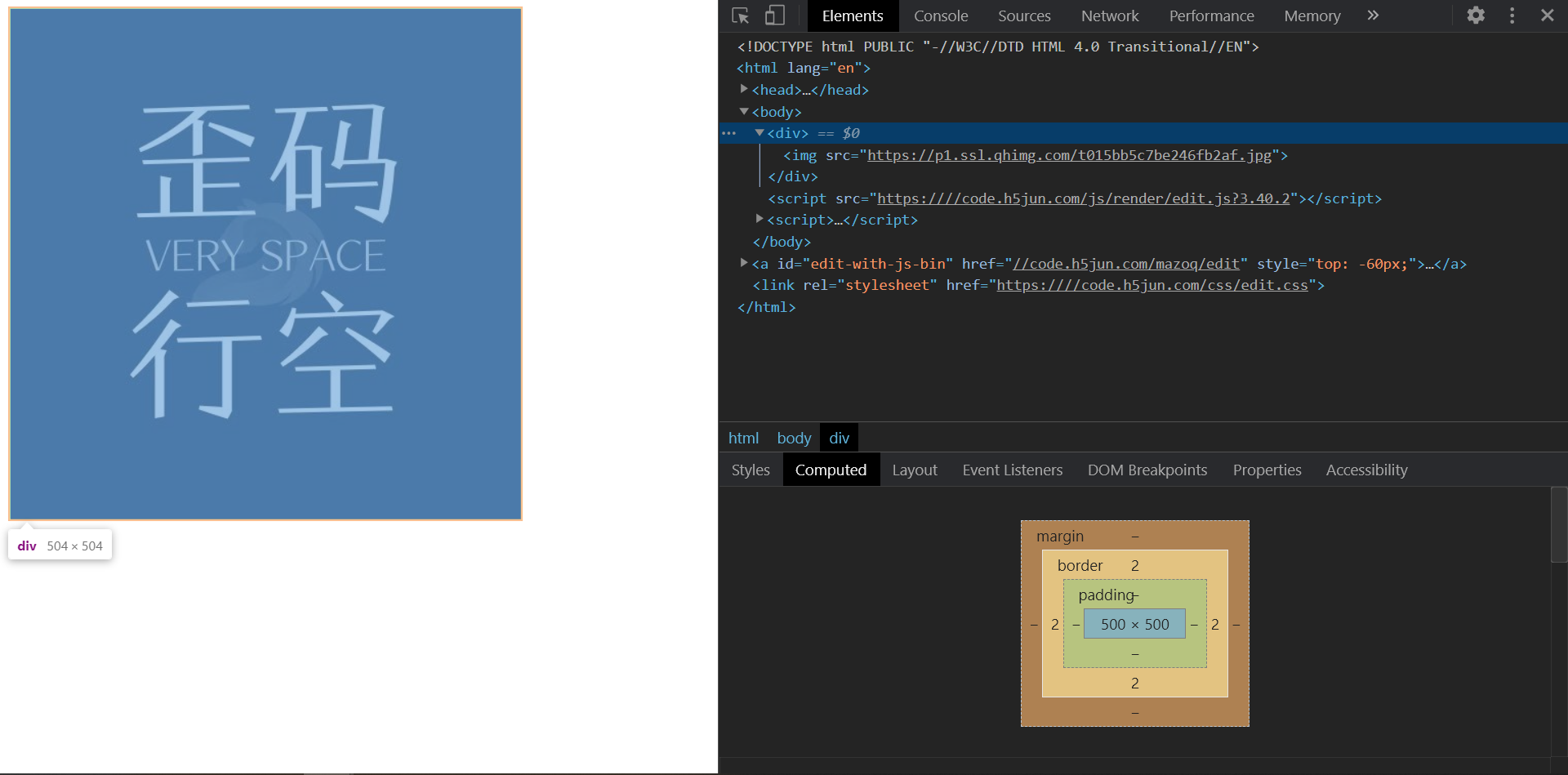
如何理解HTML语义化
- html语义化让页面的内容结构化,结构更清晰,便于对浏览器、搜索引擎解析
- 即使在没有样式CSS情况下也以一种文档格式显示,并且是容易阅读的
- 搜索引擎的爬虫也依赖于HTML标记来确定上下文和各个关键字的权重,利于SEO
- 使阅读源代码的人对网站更容易将网站分块,便于阅读维护理解。
Label的作用是什么
label标签来定义表单控制间的关系,当用户选择该标签时,浏览器会自动将焦点转到和标签相关的表单控件上。
CSS
CSS常见选择器
CSS1定义的选择器
| 选择器 | 类型 | 说明 |
|---|---|---|
| E | 类型选择器 | 选择指定类型的元素 |
| E#id | ID选择器 | 选择匹配E的元素,且匹配元素的id为“id”,E选择符可以省略。 |
| E.class | 类选择器 | 选择匹配E的元素,且匹配元素的class属性值为“class”,E选择符可以省略。 |
| E F | 包含选择器 | 选择匹配F的元素,且该元素被包含在匹配E的元素内。 |
| E:link | 链接伪类选择器 | 选择匹配E的元素,且匹配元素被定义了超链接并未被访问。例:a:link |
| E:visited | 链接伪类选择器 | 选择匹配E的元素,且匹配元素被定义了超链接并已被访问。例:a:visited |
| E:active | 用户操作伪类选择器 | 选择匹配E的元素,且匹配元素被激活 |
| E:hover | 用户操作伪类选择器 | 选择匹配E的元素,且匹配元素正被鼠标经过 |
| E:focus | 用户操作伪类选择器 | 选择匹配E的元素,且匹配元素获取了焦点 |
| E::first-line | 伪元素选择器 | 选择匹配E元素内的第一行文本 |
| E::first-letter | 伪元素选择器 | 选择匹配E元素内的第一个字符 |
CSS2定义的选择器
| 选择器 | 类型 | 说明 |
|---|---|---|
| * | 通配选择器 | 选择文档中所有元素 |
| E[foo] | 属性选择器 | 选择匹配E的元素,且该元素定义了foo属性。E选择符可以省略,表示选择定义了foo属性的任意类型的元素。 |
| E[foo=”bar”] | 属性选择器 | 选择匹配E的元素,且该元素foo属性值为“bar” |
| E[foo~=”bar”] | 属性选择器 | 选择匹配E的元素,且该元素定义了foo属性,foo属性值是一个以空格符分隔的列表,其中一个列表的值为“bar”,E选择符可以省略。 |
| E[foo!=”en”] | 属性选择器 | 选择匹配E的元素,且该元素定义了foo属性,foo属性值是一个用连字符(-)分隔的列表,值以“en”开头。 |
| E:first-child | 结构伪类选择器 | 选择匹配E的元素,且该元素为父元素的第一个子元素 |
| E::before | 伪元素选择器 | 在匹配E的元素前面插入内容 |
| E::after | 伪元素选择器 | 在匹配E的元素后面插入内容 |
| E > F | 子包含选择器 | 选择匹配F的元素,且该元素为所匹配E元素的子元素。 |
| E + F | 相邻兄弟选择器 | 选择匹配F的元素,且该元素为所匹配E元素后面相邻的位置。 |
CSS3新增选择器
| 选择器 | 类型 | 说明 |
|---|---|---|
| E[foo^=”bar”] | 属性选择器 | 选择匹配E的元素,且该元素定义了foo属性,foo属性值以“bar”开始。E选择符可以省略,表示可匹配任意类型的元素。 |
| E[foo$=”bar”] | 属性选择器 | 选择匹配E的元素,且该元素定义了foo属性,foo属性值以“bar”结束。E选择符可以省略,表示可匹配任意类型的元素。 |
| E[foo*=”bar”] | 属性选择器 | 选择匹配E的元素,且该元素定义了foo属性,foo属性值包含“bar”。E选择符可以省略,表示可匹配任意类型的元素。 |
结构伪类选择器
| 选择器 | 说明 |
|---|---|
| E:root | 选择匹配E所在文档的根元素。在(X)HTML文档中,根元素就是html元素,此时该选择器与html类型选择器匹配的内容相同。 |
| E:nth-child(n) | 选择所有在其父元素中第n个位置的匹配E的子元素。 注意,参数n可以是数字(1、2、3)、关键字(odd、even)、公式(2n、2n+3)参数的索引从1开始。 tr:nth-child(3)匹配所有表格中第3排的tr; tr:nth-child(2n+1)匹配所有表格的奇数行; tr:nth-child(2n)匹配所有表格的偶数行; tr:nth-child(odd)匹配所有表格的奇数行; tr:nth-child(even)匹配所有表格的偶数行; |
| E:nth-last-child(n) | 选择所有在其父元素中倒数第n个位置的匹配E的子元素 |
| E:nth-of-type(n) | 选择父元素中第n个位置,且匹配E的子元素。 注意,所有匹配E的子元素被分离出来单独排序。非E的子元素不参与排序。参数n可以是数字,关键字、公式。 例:p:nth-of-type(1) |
| E:nth-last-of-type(n) | 选择父元素中倒数第n个位置,且匹配E的子元素。 |
| E:last-child | 选择位于其父元素中最后一个位置,且匹配E的子元素。 |
| E:first-of-type | 选择位于其父元素中且匹配E的第一个同类型的子元素。 该选择器的功能类似于 E:nth-of-type(1) |
| E:last-of-type | 选择位于其父元素中且匹配E的最后第一个同类型的子元素。 该选择器的功能类似于 E:nth-last-of-type(1) |
| E:only-child | 选择其父元素只包含一个子元素,且该子元素匹配E。 |
| E:only-of-type | 选择其父元素只包含一个同类型的子元素,且该子元素匹配E。 |
| E:empty | 选择匹配E的元素,且该元素不包含子节点。 |
UI状态伪类选择器
| 选择器 | 说明 |
|---|---|
| E:enabled | 选择匹配E的所有可用UI元素。 |
| E:disabled | 选择匹配E的所有不可用UI元素。 |
| E:checked | 选择匹配E的所有可用UI元素。 例:input:checked匹配input type为radio及checkbox元素 |
CSS3其他选择器
| 选择器 | 说明 |
|---|---|
| E~F | 通用兄弟元素选择器类型。 选择匹配F的所有元素,且匹配元素位于匹配E的元素后面。 在DOM结构树中,E和F所匹配的元素应该在同一级结构上。 |
| E:not(s) | 否定伪类选择器类型。 选择匹配E的所有元素,且过滤掉匹配s选择符的任意元素。 s是一个简单结构的选择器,不能使用复合选择器, |
| E:target | 目标伪类选择器类型。 选择匹配E的所有元素,且匹配元素被相关URL指向。 注意:该选择器是动态选择器,只有存在URL指向该匹配元素时,样式才起效果。 例:demo.html#id |
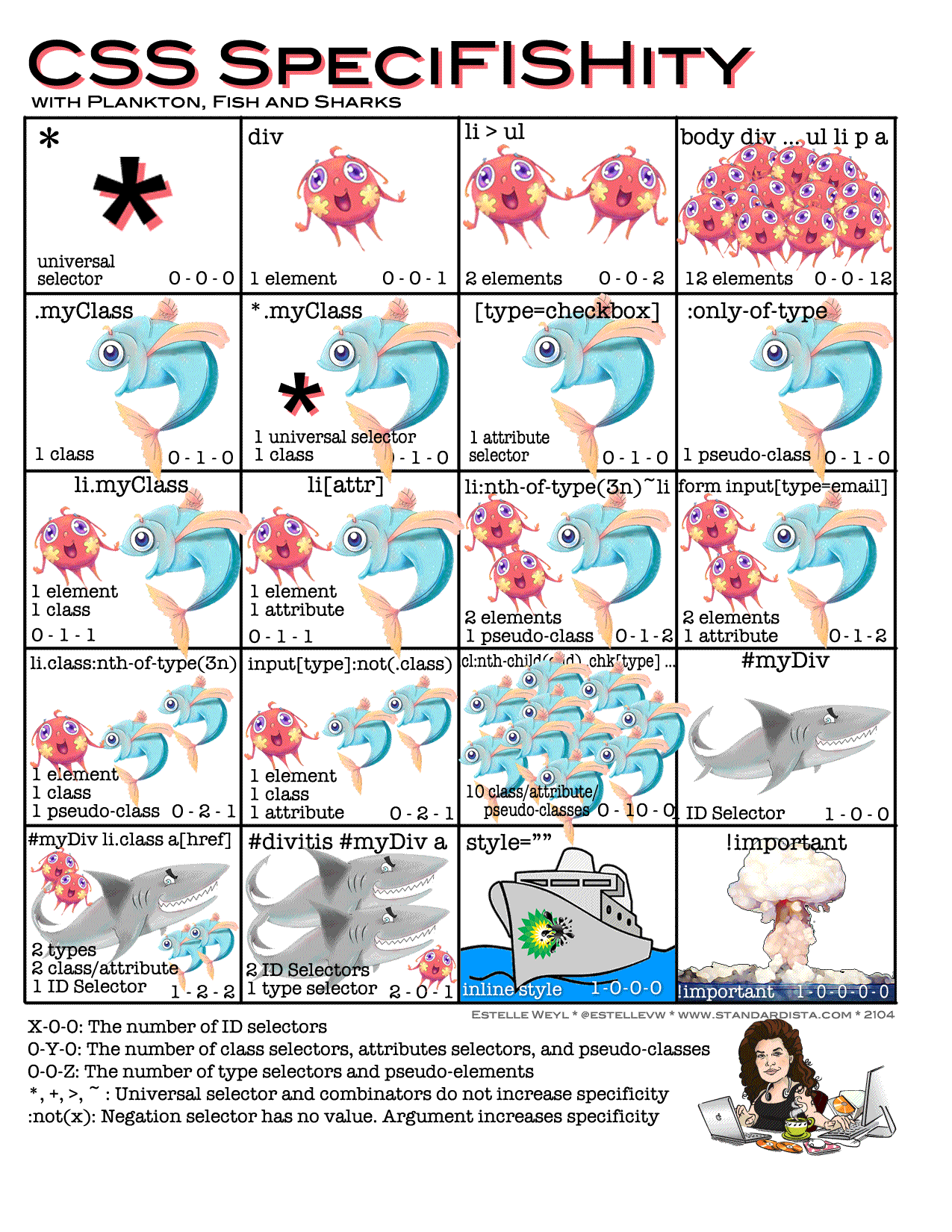
CSS常见选择器优先级
1 | 1.id选择器( # myid) |
这张图可以说非常有意思了
!important > 内联样式 > ID选择器 > 类选择器 | 属性选择器 | 伪类选择器 > 元素选择器 | 伪元素选择器 > 通配符选择器 > 继承 > 默认
link和@import的区别
@import是 CSS 提供的语法规则,只有导入样式表的作用;link是HTML提供的标签,不仅可以加载 CSS 文件,还可以定义 RSS、rel 连接属性等。@import是 CSS2.1 才有的语法,故只可在 IE5+ 才能识别;link标签作为 HTML 元素,不存在兼容性问题。
没了,下面两条其他文章有提到,但我自己测试时发现是错的
- 加载页面时,
link标签引入的 CSS 被同时加载;@import引入的 CSS 将在页面加载完毕后被加载。 link引入的样式权重大于@import引入的样式。
使用下面的代码测试
1 |
|
1 | /* index.css */ |
1 | /* index1.css */ |
结果如下
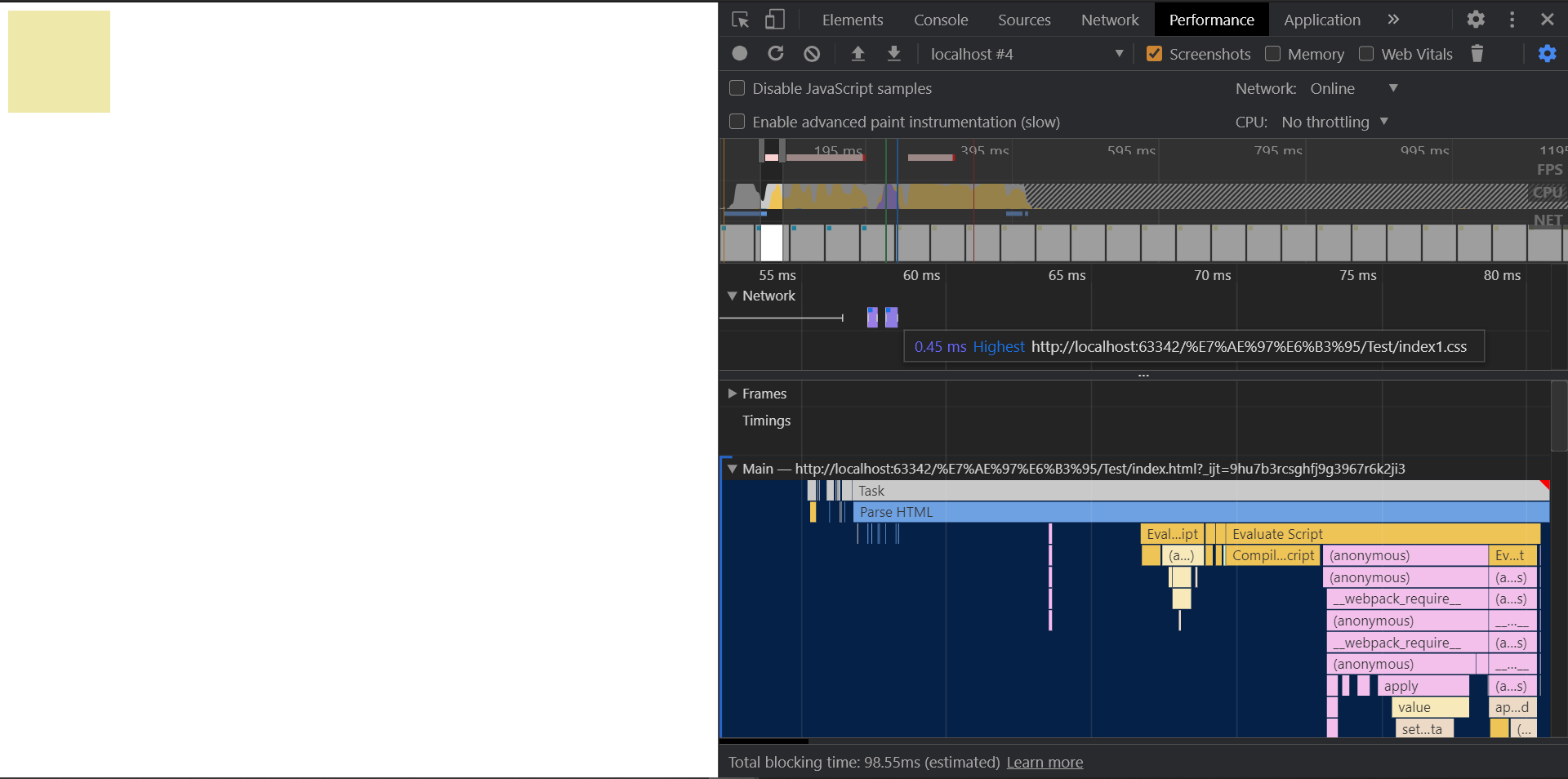
可以看到
- 两个CSS都是在
parse html中加载的,不存在@import引入的要等待页面加载结束后才加载 - 样式只是按照相同优先级后面的覆盖前面的这个规则进行覆盖,两种方式的优先级都是一样的
这个故事告诉我们不要瞎背网上的答案orz
如何修改chrome记住密码后自动填充表单的黄色背景
1 | input:-webkit-autofill, textarea:-webkit-autofill, select:-webkit-autofill { |
奇数字体和偶数字体
有些地方指出应该少使用奇数字体,原因如下
- 低版本的浏览器ie6会把奇数字体强制转化为偶数,即13px渲染为14px
- 老版本Windows的中易宋体开始只提供 12、14、16 px 这三个大小的点阵,而 13、15、17 px 时用的是小一号的点阵(即每个字占的空间大了 1 px,但点阵没变),所以看起来可能比较稀疏
不过我寻思,Vue都不支持IE8和以下的IE浏览器了emmm,好像没有必要太在意
而且知乎用的也是15px的字体,也挺好看的
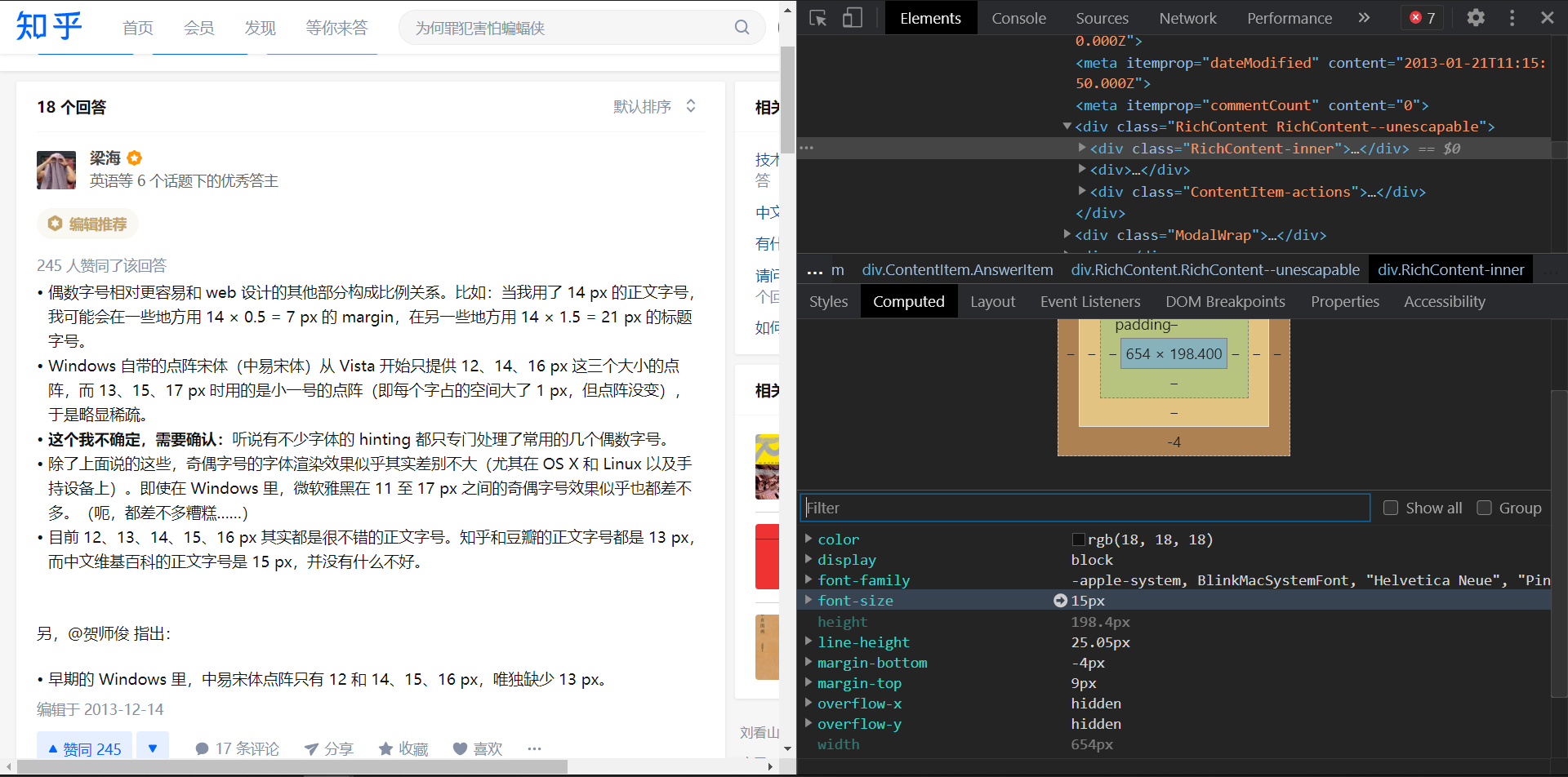
Chrome 中文界面下默认会将小于 12px 的文本强制按照 12px 显示
说是用CSS 属性 -webkit-text-size-adjust: none
不过我一试试发现被骗了啊,这玩意有限制的
- 只对chrome27.0 版本以下有效,27.0以上版本无效;
- 只对英文才有效,对中文无效。
建议使用transform
1 | transform : scale(0.9) |
不过会缩放整个元素
所以还是把小于12px的文字弄成图片吧orz
overflow: scroll不能平滑滚动怎么解决
1 | -webkit-overflow-scrolling: touch; |
貌似会开启硬件加速
JS
闭包是什么
闭包是指有权访问另一个函数作用域中变量的函数,创建闭包的最常见的方式就是在一个函数内创建另一个函数
如何实现浏览器内多个标签页之间的通信
使用
websocket使用
localstorge并在window上设置监听1
2
3
4// 这样
window.onstorage = (e) => {console.log(e)}
// 或者这样
window.addEventListener('storage', (e) => console.log(e))使用
ShareWorker
XMLHttpRequest
这篇写的很好
单页应用和多页应用
单页面应用,即一个web项目就只有一个页面,只有一个HTML文件
多页面应用,一个项目由多个完整的页面组成,有多个HTML文件。
单页应用的优点
- 有良好的交互体验。用户在访问页面时是不会频繁的去切换页面,刷新页面吗,从而避免了页面重新加载的消耗(单页应用一般是利用
JavaScript动态的变换HTML的内容)。 - 减轻服务器压力。服务器只用出数据就可以,不用管展示逻辑和页面合成,吞吐能力会提高几倍
单页应用的缺点
- SEO难度较高。SEO差的原因是页面中的内容都靠js渲染,搜索引擎难以解析页面内容
- 首屏加载(初次加载)耗时多。为实现单页
Web应用功能及显示效果,需要在首次加载页面的时候加载大量的JavaScript、CSS - 路由管理需要自己处理。由于单页
Web应用在一个页面中显示所有的内容,所以不能使用浏览器的前进后退功能,需要自己进行相关的路由处理
奇怪的运算符

概况一下就是,对+运算符
- 把左右两边转化成原始类型
- 如果一边是字符串,把另一边转成字符串做拼接
- 否则把两边都转成数字进行
+运算

对-运算符
把两边都转成数字进行运算,实际上*和/也是这么运算的
网络
常见的HTTP状态码
背不完背不完orz
1 | 1**(信息类):表示接收到请求并且继续处理 |
为什么要三次握手
原因有两个
一个是相互确认收发能力是否正常
另一个是防止网络出错导致的延时
试想使用二次握手,就会出现下面的情况
如客户端发出连接请求,但因连接请求报文丢失而未收到确认,于是客户端再重传一次连接请求。后来收到了确认,建立了连接。数据传输完毕后,就释放了连接
但客户端共发出了两个连接请求报文段,其中第一个丢失,第二个到达了服务端,但是第一个丢失的报文段只是在某些网络结点长时间滞留了,延误到连接释放以后的某个时间才到达服务端,此时服务端误认为客户端又发出一次新的连接请求,于是就向客户端发出确认报文段,同意建立连接。
此时客户端会忽略服务端发来的确认,也不发送数据,而服务端一致等待客户端发送数据,白白浪费资源。
为什么要四次挥手
先看看四次挥手的过程(实际上主动断开的一方可以是客户端也可以是服务端)
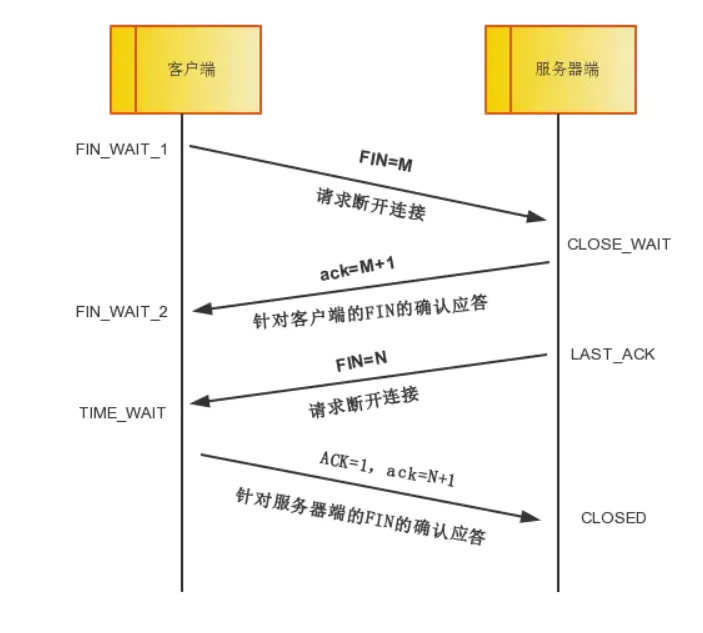
第一次挥手: Client端发起挥手请求,向Server端发送标志位是FIN报文段,设置序列号seq,此时,Client端进入FIN_WAIT_1状态,这表示Client端没有数据要发送给Server端了。
第二次挥手:Server端收到了Client端发送的FIN报文段,向Client端返回一个标志位是ACK的报文段,ack设为seq加1,Client端进入FIN_WAIT_2状态,Server端告诉Client端,我确认并同意你的关闭请求。
第三次挥手: Server端向Client端发送标志位是FIN的报文段,请求关闭连接,同时Client端进入LAST_ACK状态,表示Server端也没有数据要发给Client端了
第四次挥手 : Client端收到Server端发送的FIN报文段,向Server端发送标志位是ACK的报文段,然后Client端进入TIME_WAIT状态。Server端收到Client端的ACK报文段以后,就关闭连接。此时,Client端等待2MSL的时间后依然没有收到回复,则证明Server端已正常关闭,那好,Client端也可以关闭连接了。
另外,要注意TCP是全双工的
这就意味着,关闭连接时,当Client端发出FIN报文段时,只是表示Client端告诉Server端数据已经发送完毕了。当Server端收到FIN报文并返回ACK报文段,表示它已经知道Client端没有数据发送了,但是Server端还是可以发送数据到Client端的,所以Server很可能并不会立即关闭SOCKET,直到Server端把数据也发送完毕。
当Server端也发送了FIN报文段时,这个时候就表示Server端也没有数据要发送了,就会告诉Client端,我也没有数据要发送了,之后就会中断这次TCP连接。
为什么要等待2MSL?
- 保证TCP协议的全双工连接能够可靠关闭,由于IP协议的不可靠性或者是其它网络原因,导致了Server端没有收到Client端的ACK报文,那么Server端就会在超时之后重新发送FIN,如果此时Client端的连接已经关闭处于
CLOESD状态,那么重发的FIN就找不到对应的连接了,从而导致连接错乱,所以,Client端发送完最后的ACK不能直接进入CLOSED状态,而要保持TIME_WAIT,当再次收到FIN的收,能够保证对方收到ACK,最后正确关闭连接。 - 保证这次连接的重复数据段从网络中消失,如果Client端发送最后的ACK直接进入
CLOSED状态,然后又再向Server端发起一个新连接,这时不能保证新连接的与刚关闭的连接的端口号是不同的,也就是新连接和老连接的端口号可能一样了,那么就可能出现问题:如果前一次的连接某些数据滞留在网络中,这些延迟数据在建立新连接后到达Client端,由于新老连接的端口号和IP都一样,TCP协议就认为延迟数据是属于新连接的,新连接就会接收到脏数据,这样就会导致数据包混乱。所以TCP连接需要在TIME_WAIT状态等待2倍MSL,才能保证本次连接的所有数据在网络中消失。
GET和POST请求的区别
GET 和 POST 方法没有实质区别,只是报文格式不同。
GET 和 POST 只是 HTTP 协议中两种请求方式,而 HTTP 协议是基于 TCP/IP 的应用层协议,无论 GET 还是 POST,用的都是同一个传输层协议,所以在传输上,没有区别。
报文格式上,不带参数时,最大区别就是第一行方法名不同
- POST方法请求报文第一行是这样的
POST /uri HTTP/1.1 \r\n - GET方法请求报文第一行是这样的
GET /uri HTTP/1.1 \r\n
带参数时报文的区别呢? 在约定中,GET 方法的参数应该放在 url 中,POST 方法参数应该放在 body 中
举个例子,如果参数是 name=sakura, age=16
GET 方法简约版报文是这样的
1 | GET /index.php?name=sakura&age=16 HTTP/1.1 |
POST 方法简约版报文是这样的
1 | POST /index.php HTTP/1.1 |
也就是说,如果我不按规范来也是可以的。我们可以在 URL 上写参数,然后方法使用 POST;也可以在 Body 写参数,然后方法使用 GET。当然,这需要服务端支持(有些服务端会直接忽视掉不符合规范的数据)。
但是浏览器会对这两个请求方法做不同的限制,具体如下
| 分类 | GET | POST |
|---|---|---|
| 后退按钮/刷新 | 没有效果 | 数据会被重新提交(浏览器应该告知用户数据会被重新提交)。 |
| 缓存 | 浏览器会缓存GET请求 | 不能缓存 |
| 编码类型 | application/x-www-form-urlencoded | application/x-www-form-urlencoded,multipart/form-data等 |
| 历史记录 | 参数保留在浏览器历史记录中 | 参数不会保存在浏览器历史记录中 |
| 对数据长度的限制 | URL 的最大长度是 2048 个字符 | 请求体里的数据长度不限制 |
| 对数据类型的限制 | 只允许 ASCII 字符(毕竟URL里) | 没有限制,允许二进制数据。 |
另外,还要一点就是,GET和POST的语义不同,前者是是幂等的,没有副作用,后者是非幂等的,有副作用。
Node
Express中的中间件是怎么实现洋葱模型的
瞎模拟了一下,有手就行
1 | type AnyObject = { |
其他
CommonJS和ES6模块化的区别
前者是动态的,后者是静态的
这里的动态指的是,模块依赖关系的建立发生在代码运行阶段,而静态指的是模块依赖关系建立在代码编译阶段
在CommonJS中,require的模块路径是可以动态指定的,可以使用表达式进行运算,甚至可以使用if来判断是否加载某个模块,用for来循环加载模块,所以在代码被执行前,都不能确定明确的依赖关系,模块的导入导出都是在代码的运行阶段。
而在ES6的模块化中,导入和导出语句都是声明式的,导入的路径不能是一个表达式,而且导入,导出语句必须位于模块的顶层作用域(也就是不能放在if和for中)。所以ES Module是一种静态的模块结构,在ES6的代码编译阶段就可以分析出模块的依赖关系。
所以ES6的模块化在牺牲了一些灵活性之后换来了下面的优点
- 死代码检测和排除,也就是通过静态分析去除用不到的模块代码
- 编译器优化,在
CommonJS中,无论哪种方式,导入的都是一个对象,而ES Module支持直接导入变量,减少了引用层级,程序效率更高
前者是值拷贝,后者是动态映射
在导入一个模块时,对CommonJS来说只是获取了一个导出值的拷贝(原始值的拷贝),一旦输出一个值,模块内部的变化就影响不到这个值。
而在ES6 Module中则是值的动态映射,而且这个映射是只读的
1 | // a.js |
1 | // a.js |
所以CommonJS有下面需要注意的问题
- CommonJS 模块重复引入的模块并不会重复执行,再次获取模块直接获得暴露的 module.exports 对象
- 如果你要处处获取到模块内的最新值的话,也可以你每次更新数据的时候每次都要去更新 module.exports 上的值
- 如果你暴露的 module.exports 的属性是个对象,那就不存在这个问题了
而ES Module导出的值是动态关联的
1 | // a.js |
另外注意一点,import 命令会被 JavaScript 引擎静态分析,优先于模块内的其他内容执行
1 | console.log('a.js') |
再加上两个
- 前者可以修改导出结果,后者修改了会报错
- 前者不会被提升,后者会被提升
图片格式的问题
- BMP,是无损的、既支持索引色也支持直接色的、点阵图。这种图片格式几乎没有对数据进行压缩,所以BMP格式的图片通常具有较大的文件大小。
- GIF是无损的、采用索引色的、点阵图。采用LZW压缩算法进行编码。文件小,是GIF格式的优点,同时,GIF格式还具有支持动画以及透明的优点。但GIF格式仅支持8bit的索引色,所以GIF格式适用于对色彩要求不高同时需要文件体积较小的场景。
- JPEG是有损的、采用直接色的、点阵图。JPEG的图片的优点,是采用了直接色,得益于更丰富的色彩,JPEG非常适合用来存储照片,与GIF相比,JPEG不适合用来存储企业Logo、线框类的图。因为有损压缩会导致图片模糊,而直接色的选用,又会导致图片文件较GIF更大。
- PNG-8是无损的、使用索引色的、点阵图。PNG是一种比较新的图片格式,PNG-8是非常好的GIF格式替代者,在可能的情况下,应该尽可能的使用PNG-8而不是GIF,因为在相同的图片效果下,PNG-8具有更小的文件体积。除此之外,PNG-8还支持透明度的调节,而GIF并不支持。现在,除非需要动画的支持,否则我们没有理由使用GIF而不是PNG-8。
- PNG-24是无损的、使用直接色的、点阵图。PNG-24的优点在于,它压缩了图片的数据,使得同样效果的图片,PNG-24格式的文件大小要比BMP小得多。当然,PNG24的图片还是要比JPEG、GIF、PNG-8大得多。
- SVG是无损的、矢量图。SVG是矢量图。这意味着SVG图片由直线和曲线以及绘制它们的方法组成。当你放大一个SVG图片的时候,你看到的还是线和曲线,而不会出现像素点。这意味着SVG图片在放大时,不会失真,所以它非常适合用来绘制企业Logo、Icon等。
- WebP是谷歌开发的一种新图片格式,WebP是同时支持有损和无损压缩的、使用直接色的、点阵图。从名字就可以看出来它是为Web而生的,什么叫为Web而生呢?就是说相同质量的图片,WebP具有更小的文件体积。现在网站上充满了大量的图片,如果能够降低每一个图片的文件大小,那么将大大减少浏览器和服务器之间的数据传输量,进而降低访问延迟,提升访问体验。
- 在无损压缩的情况下,相同质量的WebP图片,文件大小要比PNG小26%;
- 在有损压缩的情况下,具有相同图片精度的WebP图片,文件大小要比JPEG小25%~34%;
- WebP图片格式支持图片透明度,一个无损压缩的WebP图片,如果要支持透明度只需要22%的格外文件大小。
- 但是目前只有Chrome浏览器和Opera浏览器支持WebP格式,兼容性不太好。
可以使用服务器判断请求头或者试着加载webp图片的方法来判断是否支持Webp格式,详情看这篇文章
参考
https://juejin.cn/post/6844904067601268744
https://juejin.cn/post/6844904070000410631
《webpack入门,进阶和调优》
